The impact of fast networks on graph analytics, part 1
This is a joint post with Malte Schwarzkopf, cross-blogged here and at the CamSaS blog.
tl;dr: A recent NSDI paper argued that data analytics stacks don’t get much faster at tasks like PageRank when given better networking, but this is likely just a property of the stack they evaluated (Spark and GraphX) rather than generally true. A different framework (timely dataflow) goes 6x faster than GraphX on a 1G network, which improves by 3x to 15-17x faster than GraphX on a 10G network.
I spent the past few weeks visiting the CamSaS folks at the University of Cambridge Computer Lab. Together, we did some interesting work, which we – Malte Schwarzkopf and I – are now going to tell you about.
Recently, a paper entitled “Making Sense of Performance in Data Analytics Frameworks” appeared at NSDI 2015. This paper contains some surprising results: in particular, it argues that data analytics stacks are limited more by CPU than they are by network or disk IO. Specifically,
“Network optimizations can only reduce job completion time by a median of at most 2%. The network is not a bottleneck because much less data is sent over the network than is transferred to and from disk. As a result, network I/O is mostly irrelevant to overall performance, even on 1Gbps networks.” (§1)
The measurements were done using Spark, but the authors argue that they generalize to other systems. We thought that this was surprising, as it doesn’t match our experience with other data processing systems. In this blog post, we will look into whether these observations do indeed generalize.
One of the three workloads in the paper is the BDBench query set from Berkeley, which includes a “page-rank-like computation”. Moreover, PageRank also appears as an extra example in the NSDI slide deck (slide 38-39), used there to illustrate that at most a 10% improvement in job completion time can be had even for a network-intensive workload.
This was especially surprising to us because of the recent discussion around whether graph computations require distributed data processing systems at all. Several distributed systems get beat by a simple, single-threaded implementation on a laptop for various graph computations. The common interpretation is that graph computations are communication-limited; the network gets in the way, and you are better off with one machine if the computation fits.0
These two positions – (i) “PageRank cannot be improved by more than 10% via a faster network”, and (ii) “graph computations such as PageRank are communication-bound, and benefit from very fast local communication” – didn’t jive with each other, and raised a bunch of questions: are these computations CPU-bound, or communication-bound, or is it perhaps more complicated than that? And shouldn’t it still be possible to make multiple computers connected by a decent network go faster than one computer?
We are going to look in to the performance of distributed PageRank using both GraphX (a graph processing framework on top of Spark) and timely dataflow, on a cluster with both 1G and 10G network interfaces.
tl;dr #1: Network speed may not matter with a Spark-based stack, but it does matter to higher-performance analytics stacks, and for graph processing especially. By moving from a 1G to a 10G network, we see a 2-3x improvement in performance for timely dataflow.
tl;dr #2: A well-balanced distributed system offers performance improvements even for graph processing problems that fit into a single machine; running things locally isn’t always the best strategy.
tl;dr #3: PageRank performance on GraphX is primarily system-bound. We see a 4x-16x performance increase when using timely dataflow on the same hardware, which suggests that GraphX (and other graph processing systems) leave an alarming amount of performance on the table.
Obviously, take all these conclusions with a grain of salt: we will discuss some caveats and design decisions that some may disagree with. However, our code is available alongside instructions, so you may try it for yourself!
Overview
We set out to understand the bottlenecks in a non-trivial computation that we understand pretty well: PageRank. To be clear, PageRank is not some brilliant computation, but it is more interesting than a distributed grep. It is a good example of computations that exchange data, aggregate data, and benefit from maintaining indexed data resident in memory. It can also be implemented in different ways, and thus helps tease out how well (or badly) a particular approach fits with a particular system.
This was also a good opportunity to try out timely dataflow in Rust, which is both a port to Rust and an extension of the timely dataflow paradigm in Naiad. Timely dataflow in Rust had only been run on a laptop so far, so this was a good chance to shake some bugs out.
Additionally, the Cambridge Computer Lab has a new “model data centre”, which is a modern cluster equipped with 10G networking kit, and we wanted to see how fast this Rust code can go. As it turns out, it now moves pretty briskly. You’ll see.
PageRank
PageRank is a not-wildly-complicated graph computation: the idea is that each vertex starts with some amount of real-valued “rank”, which it repeatedly shares along the directed edges to its neighbors. If one keeps doing this for long enough, the real-valued ranks start to stabilize.
Here is a straightforward, serial PageRank implementation in Rust:
fn pagerank<G>(graph: &G: Graph, vertices: usize, alpha: f32)
{
// mutable per-vertex state
let mut src = vec![0f32; vertices];
let mut dst = vec![0f32; vertices];
let mut deg = vec![0f32; vertices];
// determine vertex degrees
for (x,_) in graph.edges() { deg[x] += 1f32; }
// perform 20 iterations
for _iteration in (0 .. 20) {
// prepare src ranks
for vertex in (0 .. vertices) {
src[vertex] = alpha * dst[vertex] / deg[vertex];
dst[vertex] = 1f32 - alpha;
}
// do the expensive part
for (x,y) in graph.edges() { dst[y] += src[x]; }
}
}If we look at the code, the computation manipulates per-vertex state (preparing src[vertex] and dst[vertex], using deg[vertex]), and then swings through graph, increasing dst[y] by src[x] for each graph edge (x,y).
The only part of this computation that makes parallelization difficult is updating dst[y]: because the edges may link any pairs of vertices, we don’t have an a priori partitioning of responsibility for these updates. So we’ll have to do that.
A Distributed PageRank
We want to map this computation across multiple workers (threads, processes, or computers), and fortunately there are several fairly simple ways to do this. The most common approach is to partition responsibility for each vertex across the workers, so that each worker is responsible for a roughly equal number of vertices.1 We will assign the responsibility for processing vertex v to worker v % workers.
To partition the computation among workers, we also need to partition the relevant state (inputs and intermediate data) as well. The input to the computation is just a set of edges, so we must make sure that edge (x, y) makes its way to worker x % workers.
Once we have distributed all the edges to the workers, the PageRank computation is just a matter of repeatedly applying the per-vertex updates, which each worker can do independently, and then determining and communicating the updates to the ranks of other vertices.
Each worker prepares a message of the form (y, src[x]), indicating the intended update, rather than directly applying += to the ranks. These updates are then exchanged between the workers, i.e., updates to a vertex y are sent to worker y % workers.
Implementation #1: Send everything
This will be our first implementation, which we will quickly discard as being hilariously inefficient. For every edge (x, y) at a vertex, we prepare a message (y, rank) indicating interest in performing a += operation for the edge destination y. We exchange all of these messages, sending each to the worker in charge of the recipient vertex.
The figure below illustrates how this would proceed in a setting with four workers (w0 to w3) in two processes (P0 and P1).
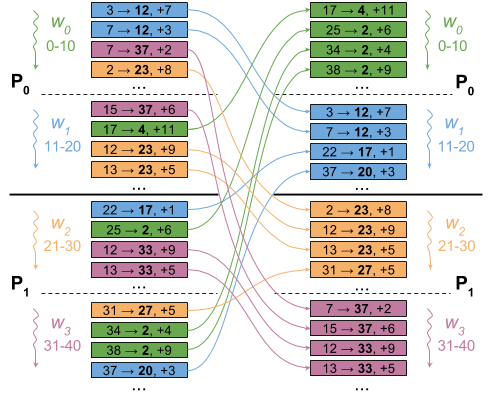
However, this approach needs to send some data across the network for every edge in the graph. That would certainly result in some serious communication,2 and 10G would look pretty good compared to 1G. However, we would only be able to conclude that a fairly naïve implementation is communication-bound. Let’s see if we can do better.
Implementation #2: Worker-level aggregation
Recall that each worker manages multiple vertices. Their edges may well have destinations in common, so each worker can accumulate the messages for each destination, and send just one message for each distinct destination. The worker can accumulate these updates into a hash table, or a large sparse vector (proportional to the number of vertices in the entire graph), but there is a much simpler way.
Each worker groups its edges by destination, rather than by source. By so doing, a worker can iterate through its destinations, accumulate its updates from each source rank, and then issue one update for the destination.
The single-threaded interpretation of this code might look like this:
// replaces "for (x, y) in graph.edges() { dst[y] += src[x]; }"
for (y, xs) in graph_transpose.edges() {
dst[y] += xs.map(|x| src[x]).sum();
}Because each worker only has edges from vertices x equal modulo workers, each value of x / workers is distinct. We can compact src by a factor of workers, accessing src[x / workers] instead of src[x]. Compared to the source-grouped approach, the code does random access into a small vector src rather than a large vector dst, which benefits locality.
The figure below illustrates this: each worker merges updates for the same destination (bold number) into a single update. As a result, this example four-worker setup ends up exchanging only 12 messages, instead of 16 in the naïve version.
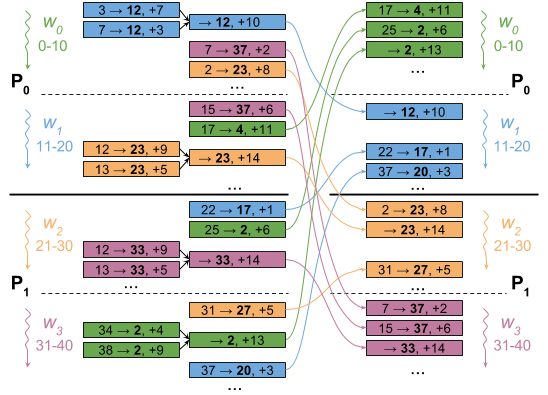
Moreover, this approach also produces outputs as it goes, which allows workers to overlap communication with communication: a worker can start telling other workers about its updates right away, using the network at the same time as the rest of the computer.
Implementation #3: Process-level aggregation
The worker-level aggregation implementation (#2, above) is our best-performing implementation for a 10G network, but it still sends quite a bit of data.3 To more fairly compare 1G and 10G networks, we can aggregate a bit more aggressively and move aggregation to the process level to further reduce the amount of data transmitted. This, however, comes at the expense of more computation and more synchronization, since process-level aggregates across multiple workers must await all data from each worker. This reduces the overlapping of computation and communication that we can do, but we send less data overall.
Again, the figure illustrates this: after we have aggregated updates at the worker level, we also aggregate them at the process level. In the example, this reduces the number of messages from 12 to 9.
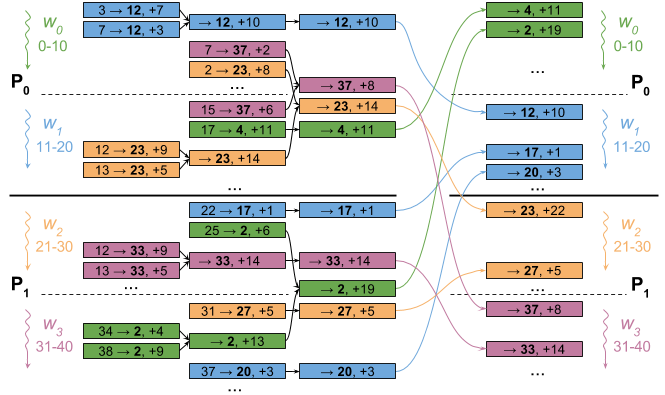
We could potentially try and make this implementation even smarter, cutting computation and overlapping communication. However, as we will show in part two of our investigation, we cannot expect a 1G network to win out over 10G even with infinitely fast aggregation.
Evaluation
Let’s see how well our implementations work!
We evaluate the time to do twenty iterations of PageRank on the CamSaS cluster,4 using Spark/GraphX 1.4 and our timely dataflow implementation.
We use two graphs, those used by the GraphX paper: a 1.4B edge graph of Twitter followers (twitter_rv), and a 3.7B edge graph of web links (uk_2007_05). The uk_2007_05 graph is also the one used for the results shown in the NSDI slide deck.
Some baseline measurements
Before we start, let’s think about existing baselines that should give some context.
Below, we show previously reported measurements from Spark and GraphX, as well as the runtime of GraphX on our cluster, and the runtime of two single-threaded implementations (from the COST paper).
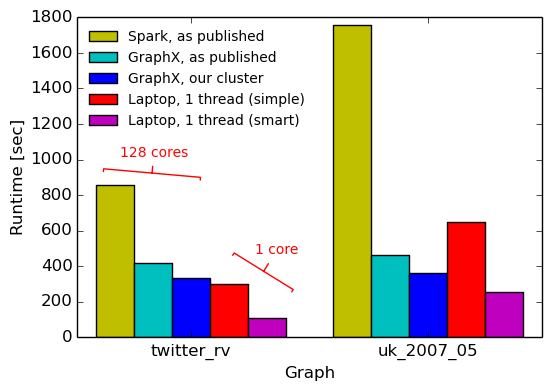
| System | source | cores | twitter_rv | uk_2007_05 |
|---|---|---|---|---|
| Spark | GraphX paper | 16x8 | 857s | 1759s |
| GraphX | GraphX paper | 16x8 | 419s | 462s |
| GraphX | measured on our cluster | 16x8 | 334s | 362s |
| Single thread (simpler) | COST paper | 1 | 300s | 651s |
| Single thread (smarter) | COST paper | 1 | 110s | 256s |
So far, nothing new: the measurement on our cluster confirms that the numbers from the GraphX paper can be reproduced,5. Moreover, the laptop performs pretty well even though it’s using only one CPU core, rather than 128. On the twitter_rv graph, the single-threaded implementation always beats the distributed implementations, and on the uk_2007_05 graph, the simple single-threaded implementation is only ~50% slower than GraphX (at 128x less resources!). The smarter single-threaded implementation with a Hilbert space-filling curve graph layout always beats the distributed systems by between 30% and 3x.
Is that bad news for distributed graph processing generally? Let’s see.
A timely dataflow implementation
Let’s take our data-parallel implementation out for a spin. We’ll start with just a single machine, and move from one core to multiple cores. We measure the total elapsed time (first graph), and the average per-iteration time of the last ten iterations (second graph). For reference, we also show the results for GraphX, and the simple single-threaded implementations (as horizontal bars).
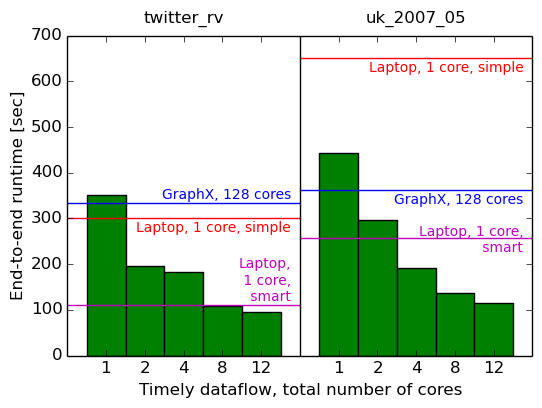
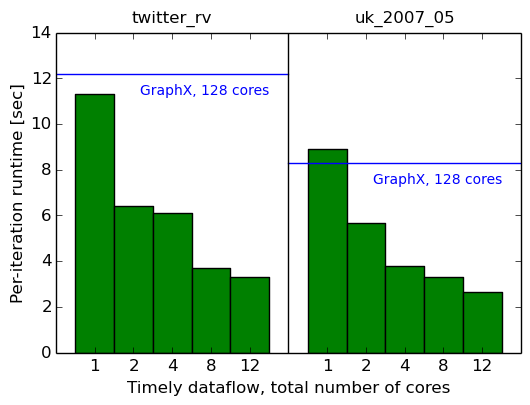
| System | cores | twitter_rv | uk_2007_05 |
|---|---|---|---|
| Timely dataflow | 1 | 350.7s (11.33s) | 442.2s (8.90s) |
| Timely dataflow | 2 | 196.5s (6.39s) | 297.3s (5.67s) |
| Timely dataflow | 4 | 182.4s (6.12s) | 192.0s (3.78s) |
| Timely dataflow | 8 | 107.6s (3.70s) | 137.1s (3.29s) |
| Timely dataflow | 12 | 95.0s (3.32s) | 114.5s (2.65s) |
Well, this is good: with one thread, we still perform similarly as GraphX at 128, and we outperform the simple single-threaded measurement with just two threads6, and we outperform the smart single-threaded measurement with eight threads.7
This suggests that parallelism inside a single machine, at least, helps make this computation go faster. Maybe multiple computers, with all that networking in between, end up being slower though?
Multiple computers: 1G vs. 10G
Let’s now see what happens when we distribute the computation over multiple computers. Here we have the choice of using either a 1G network interface or a 10G network interface; we will measure both, revealing the performance gains that 10G brings (if any).
In addition to the worker-level aggregation implementation from above, we also include measurements for process-level aggregation on a 1G network (labelled “1G+”). This is more representative of a 1G-optimized implementation, and matches what GraphX does.
For each configuration, we again report the elapsed time to perform twenty iterations (first graph), and the average of the final ten iterations (second graph). Because GraphX and our implementation have different one-off start-up costs, the average iteration time when the computation is running is probably the fairest metric for comparison.
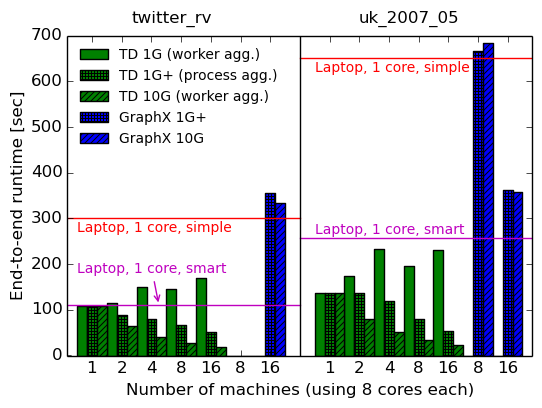
| System | cores | 1G | 1G+ | 10G | 10G speedup over 1G+ | |
|---|---|---|---|---|---|---|
| total | per-iteration | |||||
| Timely dataflow | 1x8 | 107.6s (3.70s) | 107.6s (3.70s) | 107.6s (3.70s) | – | – |
| Timely dataflow | 2x8 | 115.2s (4.66s) | 89.0s (3.51s) | 65.6s (2.34s) | 1.36x | 1.50x |
| Timely dataflow | 4x8 | 149.4s (6.77s) | 80.9s (3.33s) | 40.6s (1.49s) | 1.99x | 2.23x |
| Timely dataflow | 8x8 | 145.4s (6.60s) | 66.5s (2.86s) | 27.6s (1.05s) | 2.41x | 2.72x |
| Timely dataflow | 16x8 | 169.3s (7.51s) | 51.8s (2.30s) | 19.3s (0.75s) | 2.68x | 3.07x |
| GraphX | 16x8 | 354.8s (13.4s) | 333.7s (12.2s) | 1.06x | 1.10x | |
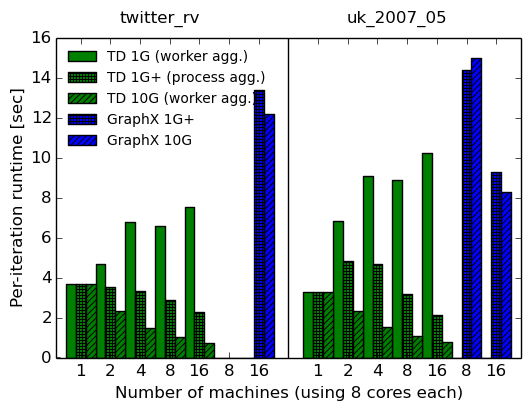
| System | cores | 1G | 1G+ | 10G | 10G speedup over 1G+ | |
|---|---|---|---|---|---|---|
| total | per-iteration | |||||
| Timely dataflow | 1x8 | 137.1s (3.29s) | 137.1s (3.29s) | 137.1s (3.29s) | – | – |
| Timely dataflow | 2x8 | 173.3s (6.82s) | 135.8s (4.82s) | 80.7s (2.31s) | 1.68x | 2.09x |
| Timely dataflow | 4x8 | 231.9s (9.06s) | 119.1s (4.67s) | 51.4s (1.54s) | 2.32x | 3.03x |
| Timely dataflow | 8x8 | 196.4s (8.87s) | 80.1s (3.18s) | 34.1s (1.07s) | 2.35x | 2.97x |
| Timely dataflow | 16x8 | 231.2 (10.25s) | 53.9s (2.13s) | 23.7s (0.76s) | 2.27x | 2.80x |
| GraphX | 8x8 | 666.8s (14.40s) | 682.6s (15.00s) | 0.98x | 0.96x | |
| GraphX | 16x8 | 361.8s (9.30s) | 357.9s (8.30s) | 1.01x | 1.12x | |
Phew, that’s a lot of data! There are a few important observations that we can draw from them, though:
-
Making the network faster does not improve GraphX’s performance much (at most 10-12%), which confirms the observations of the NSDI paper.
-
Making the network faster does improve timely dataflow’s performance (by 2-3x), which limits the generality of the conclusions of the NSDI paper.
-
Communication cost does not dominate GraphX’s performance, but it does dominate the timely dataflow performance, meaning graph computations can be communication-bound on a good implementation.
-
Nevertheless, performance strictly improves as we add machines, invalidating the claim that distributed systems will not be faster than a single machine when running a communication-bound graph computation on a graph that fits into the machine.
-
Worker-level aggregation has the opposite impact on a 10G network and a 1G network: on 10G, it yields improvements, but on 1G, it makes things slower. Moreover, at 10G, worker-level aggregation outperforms process-level aggregation (not shown in graphs), despite sending more data.
-
GraphX scales well from eight to sixteen machines on the
uk_2007_05graph, but as the COST paper has suggests, this scalability could just come from parallelizable overheads. -
Timely dataflow on a 10G network outperforms GraphX by up to 16x on the per-iteration runtime using 16 machines (16.27x for
twitter_rv, and 10.92x foruk_2007_05).
Those results allow us to answer our questions from the beginning, as we will see now.
Conclusion (for the moment)
This concludes the first part of our investigation. Apparently both 10G networks and distributed data processing systems are useful for PageRank. Phew. Existential crisis averted!
As we have seen, the three implementations (GraphX and the two timely dataflow ones) have different bottleneck resources. GraphX does more compute and is CPU-bound even on the 1G network, whereas the leaner timely dataflow implementations become CPU-bound only on the 10G network. Drawing conclusions about the scalability or limitations of either system based on the performance of the other is likely misguided.
Fast 10G networks do help reduce reduce the runtime of parallel computations by significantly more than 2-10%: we’ve seen speedups up to 3x going from 1G to 10G. However, the structure of the computation and the implementation of the data processing system must be suited to fast networks, and different strategies are appropriate for 1G and 10G networks. For the latter, being less clever and communicating more sometimes actually helps.
Distributed data processing makes sense even for graph computations where the graph fits into one machine. When computation and communication are overlapped sufficiently, using multiple machines yields speedups up to 5x (e.g., on twitter_rv, 1x8 vs. 16x8). Running everything locally isn’t necessarily faster.
Moreover, we’ve shown that we can make PageRank run 16x faster per iteration using distributed timely dataflow than using GraphX (from 12.2s to 0.75s per iteration). This tells us something about how much scope for improvement there is even over numbers currently considered state-of-the-art in research!
In part two, we will follow up with a more in-depth analysis of why timely dataflow is so much faster than GraphX. We will look at their respective resource usage over the runtime of the computation, and investigate via a lower-bound analysis whether it is at all possible to make a 1G network outperform a 10G one by doing cunning aggregation (spoiler: it’s not!).
Come back for more in a few days!
0 – This view is even common with those who build distributed graph processing systems: a few months ago, Reynold Xin (GraphX co-author, now at Databricks) indicated that, for communication-bound graph workloads that fit into a machine, there is no point in going distributed. That’s a somewhat surprising position: surely, we would expect a distributed graph processing system (such as GraphX) and a decent network to outperform a laptop on graph problems? Maybe Reynold is saying that “systems like GraphX are designed for graphs that are too large to fit into a single machine; there is no benefit to using them on ones that fit into a machine”. That’s a reasonable view to take, although the fact that all known GraphX results are on such graphs suggests that systems need to be evaluated using larger graphs. In either case, we later show that a distributed system does outperform a single machine even for graphs that do fit into the machine.
1 – Some graph processing systems (e.g., PowerGraph) use far more complex and cunning schemes in order to balance the amount of work each worker needs to do. In practice, this doesn’t seem necessary, as we will see.
2 – If we represent the edge destination by a 32-bit integer and the update value by a single-precision float, we’d end up with each machine sending and receiving ~15 GB of messages per iteration when processing the widely-used twitter_rv graph. Clearly not a good plan.
3 – About 3 GB per iteration for each machine on the twitter_rv graph.
4 – The CamSaS cluster consists of 16 machines, each equipped with an Intel Xeon E5-2430Lv2 CPU (12 hyperthreads, 2.4 GHz), 64 GB DDR3-1600 RAM, a Micron P400m-MTF SSD for the root file system and a Toshiba MG03ACA1 7,200rpm harddrive for the data, and both an onboard 1G NIC and an Intel X520 10G NIC. We run the default Ubuntu 14.04 (trusty) Linux kernel 3.13.0-24, and the harddisk is partitioned using the ext4 file system. We use the standard Spark 1.4 distribution, which includes GraphX.
5 – We suspect that our results are slightly better than those in the GraphX paper because we use dedicated machines (as opposed to m2.4xlarge EC2 instances).
6 – You might wonder why this single-threaded measurement is slower than the simple single-threaded one from before: it’s because structuring the program as dataflow adds some overhead.
7 – The smarter single-threaded implementation uses an “exotic” graph layout (based on a Hilbert space-filling curve); although this technique could be applied to timely dataflow, we won’t use it in the distributed implementation in this post.