Timely dataflow: core concepts
This is the second post in a series on timely dataflow. The first post overviewed some of the context for timely dataflow, and suggestions at new directions. This post will start to detail some of the moving parts of the new hierarchical approach.
Our plan is to organize timely dataflow graphs hierarchically, into nested scopes, each of which can be implemented by other timely dataflow graphs. This has several advantages, mostly due to the layer of abstraction hiding details that other parts of the outer timely dataflow graph need not know. On the other hand, we will need to think carefully about the abstraction boundary to avoid giving up precision.
Approach
Whereas Naiad maintained a flat view of the timely dataflow graph, with counts for each (location, timestamp) pair indicating unfinished work, we will need to take a different approach. Rather than present such fine detail about where unfinished work lives to all participants, we will use the hierarchical structure to simplify the information.
Each scope will project its unfinished work to its outputs, reporting for each output the timestamps at which messages might possibly emerge. As it performs work, it will communicate progress to the outer timely dataflow graph in the form of changes to the counts for (output, timestamp) pairs.
Similarly, unfinished work and progress made elsewhere in the graph is first projected to the scope’s inputs before it is communicated to the subgraph.
An example
To take an example we borrow an enormous figure from the Naiad paper.
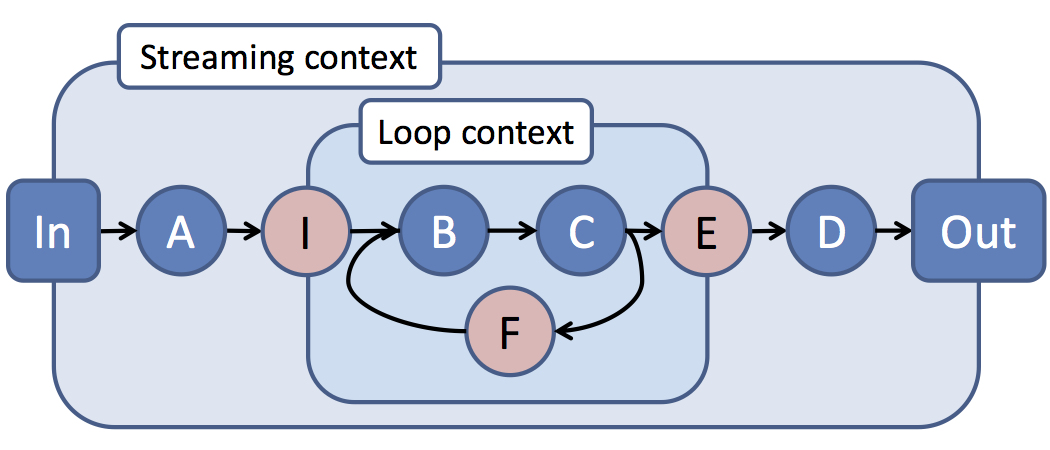
In this example we have two contexts, or “scopes” as we’ll call them: the outer “streaming” scope and the inner “loop” scope. While the inner loop scope may progress rapidly, in the outer streaming scope vertex D only needs to be informed when some externally visible progress is made. Specifically, when the output of the inner loop scope will no longer produce messages bearing a specific timestamp.
In fact, the outer streaming scope doesn’t need to know much of anything about the inner loop scope, other than it has one input and one output, and whenever it makes externally visible progress.
Our plan is just to structure the progress tracking mechanisms along these lines, reporting progress upwards having projected out any irrelevant detail and coalesced (and often cancelled) the results.
Generally, there are other things it will be helpful for the outer scope to know that this figure doesn’t demonstrate especially well. If the inner scope had multiple inputs and outputs, it would be helpful to know which inputs connected which outputs. If the inner scope had an exogenous source of input data, it would need to warn the outer scope to expect it. We will sort out these details.
Core traits
Three traits lie at the core of our timely dataflow approach: Timestamp, PathSummary, and Scope.
Each scope has its own timestamp and path summary types, implementing the corresponding traits.
The Timestamp trait
The Timestamp trait represents a type suitable for use as a message timestamp. In Naiad this role was played by a sequence of unsigned integers. We plan to admit more general timestamps, but with some constraints, specifically (from the code):
trait Timestamp: PartialOrd+Eq+PartialEq+Copy+Default+Hash+Show+Send+'static { }This is something of a mess, and strictly speaking not all of the constraints are necessary. Just helpful.
The most relevant constraint is PartialOrd, which provides for methods le, lt, ge, gt, for comparing two elements of the same type. Types implementing Timestamp must be partially ordered.
The PathSummary trait
The PathSummary trait is parameterized by a type implementing Timestamp. It indicates how the timestamp should be expected to advance as it moves from one location to another in a timely dataflow graph. It also provides support for combining two summaries (summarizing the concatenated paths).
trait PathSummary<T> : PartialOrd+Eq+Copy+Clone+Show+Default+'static
{
fn results_in(&self, timestamp: &T) -> T; // advances a timestamp
fn followed_by(&self, other: &Self) -> Self; // composes two summaries
}Path summaries allow us to translate events at some distant location to the event’s implications locally. If a distant vertex finishes processing the last of its inputs and produces no outputs, which timestamp (or timestamps) should be decremented locally?
To summarize all paths from one location to another, we exploit the fact that types implementing PathSummary are partially ordered, and that we are interested in the earliest timestamps that might emerge. Any set of path summaries can be reduced down to those elements that are not strictly less than some other set element, which we facilitate with the Antichain<S> structure.
It is likely that the trait will be updated as additional constraints are discovered. For example, it is very likely that results_in should return either Option<T> or Iterator<T> types rather than single elements. Otherwise, it may be difficult to accommodate bounded loops that discard messages once their timestamp exceeds the loop bound. Other similar unsupported patterns likely exist.
The Scope trait
The Scope trait is where the pieces start to come together. A scope represents an element in a timely dataflow graph, as seen from the outside world (or its parent scope). A scope is parameterized by a timestamp type T and a path summary type S. To implement the trait, a type must provide several methods, which we will soon detail (some diagnostic methods are elided).
trait Scope<T: Timestamp, S: PathSummary<T>> : 'static
{
fn inputs(&self) -> uint; // number of inputs
fn outputs(&self) -> uint; // number of outputs
// get and set summary information as part of set-up.
fn get_internal_summary(&mut self) -> (Vec<Vec<Antichain<S>>>,
Vec<Vec<(T, i64)>>) -> ();
fn set_external_summary(&mut self, summaries: Vec<Vec<Antichain<S>>>,
external: &Vec<Vec<(T, i64)>>) -> ();
// push and pull progress information at run-time.
fn push_external_progress(&mut self, external: &Vec<Vec<(T, i64)>>) -> ();
fn pull_internal_progress(&mut self, internal: &mut Vec<Vec<(T, i64)>>,
consumed: &mut Vec<Vec<(T, i64)>>,
produced: &mut Vec<Vec<(T, i64)>>) -> bool;
}This definition is something of a mouthful, but I hope by the end of the post the reasons for each of the parts will become clearer.
Inputs and outputs
Each scope is, to the outside world, a vertex that consumes and produces messages timestamped by T. The first thing the outside world will need to know is the shape of the scope: how many inputs does it have, and how many outputs does it have. While not conceptually deep, all further communication between the scope and the outer world will be in terms of these inputs and outputs.
Initialization
Two methods are used as part of initializing the computation, the scope summarizing itself to the outer world, and the outer world summarizing itself back to the scope. Because of the hierarchical structure, scopes first summarize themselves to their parent scope, who eventually has enough information to summarize the structure around the scope back to the scope itself.
These summaries include both what the scope (and the outer world) are capable of doing to messages received at their inputs in terms of messages produced at their outputs, and also any initial counts of timestamped messages at each output.
The first method is get_internal_summary, which asks the scope for path summaries for each of its (input, output) pairs, as well as initial counts at each of its outputs for each timestamp.
fn get_internal_summary(&mut self) -> (Vec<Vec<Antichain<S>>>,
Vec<Vec<(T, i64)>>) -> ();The result is simply the pair of summaries for each input to each output, and the list for each output of increments to counts for each timestamp.
The second method is set_internal_summary, which reports back to the scope the path summaries from each of its outputs back to its inputs, as well as the initial counts for each of its inputs.
fn set_external_summary(&mut self, summaries: Vec<Vec<Antichain<S>>>,
external: &Vec<Vec<(T, i64)>>) -> ();The two arguments are the counterparts to the returned values above: path summaries from each of the scope’s outputs to each of the scope’s inputs, and initial counts at each of the scope’s inputs.
Runtime
Once the computation has begun, the outer world interacts with the scope in two ways: it notifies the scope of progress made in the outer world, and it requests information about progress made in the scope itself. These are the push_external_progress and pull_internal_progress methods.
The first of these two methods is relatively simple: it communicates to the scope a list of updates to timestamp counts for each of its inputs. These updates communicates progress in the outer world projected down to the scope’s inputs.
fn push_external_progress(&mut self, external: &Vec<Vec<(T, i64)>>) -> ();The method does not return anything, reflecting our desire to have this be asynchronous communication: the notification is not coupled with a response, it is simply sent to the scope from the outer world with the hope that progress will be made in the future.
The second method is slightly more complicated, at least in signature. Its role is to retrieve information from the scope about progress it has made, so that the system as a whole may advance.
fn pull_internal_progress(&mut self, internal: &mut Vec<Vec<(T, i64)>>,
consumed: &mut Vec<Vec<(T, i64)>>,
produced: &mut Vec<Vec<(T, i64)>>) -> bool;The arguments are vectors meant to be populated, indicating (respectively) the changes to any internal work projected to the scope’s outputs, the numbers of messages consumed at each of the scope’s inputs, and the numbers of messages produced at each of the scope’s outputs. The method returns a bool indicating whether there is unreported work that may not result in output messages that should prevent the computation from shutting down (for example, vertices with side-effects but no outputs).
This method collects three types of updates together because it is important for correctness that two types of updates occur together:
- Consuming an input message resulting in more internal work (consuming -> internal).
- Producing an output message resulting in less internal work (internal -> producing).
If either of these two become decoupled, it is possible the outer world may have an incomplete (and incorrect) view of the state of the scope. For example, if the scope acknowledges consuming an input message but does not indicate the new internal work, the outer scope may reasonably assume there is none, and communicate incorrect progress information to others. Likewise, if internal work is retired producing an output message, there is no reason to believe the outside world will know about the message in a timely fashion unless told by the scope itself.
While we might have broken the above into two pull_internal methods, there is a nice symmetry in having one method for each direction of information flow. Moreover, there does not yet seem to be an advantage in soliciting only a subset of progress information from a scope. The scope can report what it wants to report.
Next steps
We’ve described the interfaces currently in place for our hierarchical implementation of timely dataflow. There is still a lot to say about how to implement scopes, especially the generic logic for a scope which wraps a connected collection of other scopes. We’ll talk about this next, and almost certainly surface details that are still up for discussion.